This is the second part of my Kapow vs UiPath series. If you haven’t checked out the first article yet, please do so here. This week I am going to focus on one of the larger bits and pieces of RPA: Web Automation.
Web Automation
Introduction
Automatic interaction with web pages isn’t exactly a new concept – tools like curl and wget have been around for years, decades even (wget was released in 1996). However, they traditionally downloaded a web page in text format – HTML – and then left DOM traversal and extraction up to you. So, you had to use a scripting or programming language to turn raw data into information. With the advent of RPA and all the hype it caused we see plenty of graphical, mostly web-based tools for scraping – services such as dexi.io or import.io were born, and even before that frameworks such as Scrapy helped you automating the web. Some were able to interpret JavaScript, some were and still are not – and can you imagine any web application nowadays not running JavaScript?
But enough with the history lesson, back to 2018: scraping isn’t good enough nowadays – you want to interact with web applications. That might be just clicking by a button, but can be as complex as dealing with infinite scrolling, handling web servers that block your IP after a series of requests, dealing with JavaScript, and much more.
General Approach
The most striking difference between Kapow and UiPath is the methodology used to interact with web pages. Kapow uses a built-in engine, while UiPath essentially relies on using a browser in the same way a human would (with some browsers requiring you to install a Plugin which appears to be altering the DOM to make interactions easier for UiPath). So, technical speaking UiPath uses Desktop Automation to interact with any web page via a browser, while Kapow has a built-in engine.
[Update: as Daniel mentioned, Chromium is not used as the default browser engine in Kapow – yet it can be used separately with local Device Automation. The following examples are not based on said engine.]
Conclusion & Verdict
Having an embedded browser puts Kapow at an advantage: a single Kapow server can work with as many pages and sessions as your system resources would allow. You can parse dozens of pages in parallel at the same time without the need of any additional client. However, this strength may also be a weakness: sometimes you want a robot to “prepare” a web page, and then have a user make the final decision (think of the robot putting items in your basket, but the human wants to push the “Buy” button). UiPath can do this, all you’d need to do is to connect to the Windows machine., Kapow needs a different channel or technology to ask the individual.
Given that this is a special use case and – when you’re doing lots of Web Automation – Kapow will reduce the need of physical machines and Windows license, Kapow is the clear winner here.
Interacting with the DOM
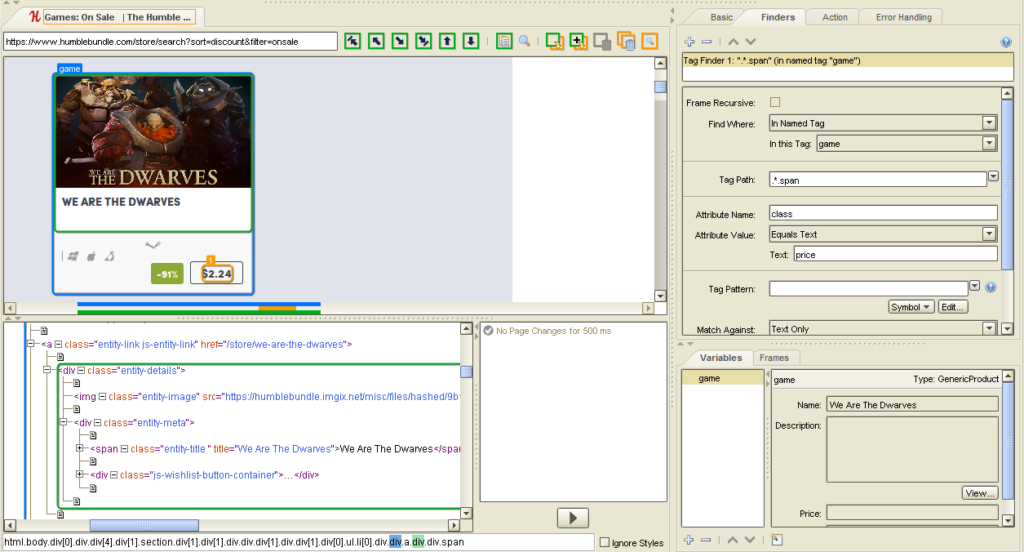
Kapow’s way of presenting a web page is the same as presenting desktop applications, Excel and PDF files: the whole page is displayed in the viewer that’s part of Design Studio along with the HTML. The currently selected item, a div with the class entity-details, is being highlighted.
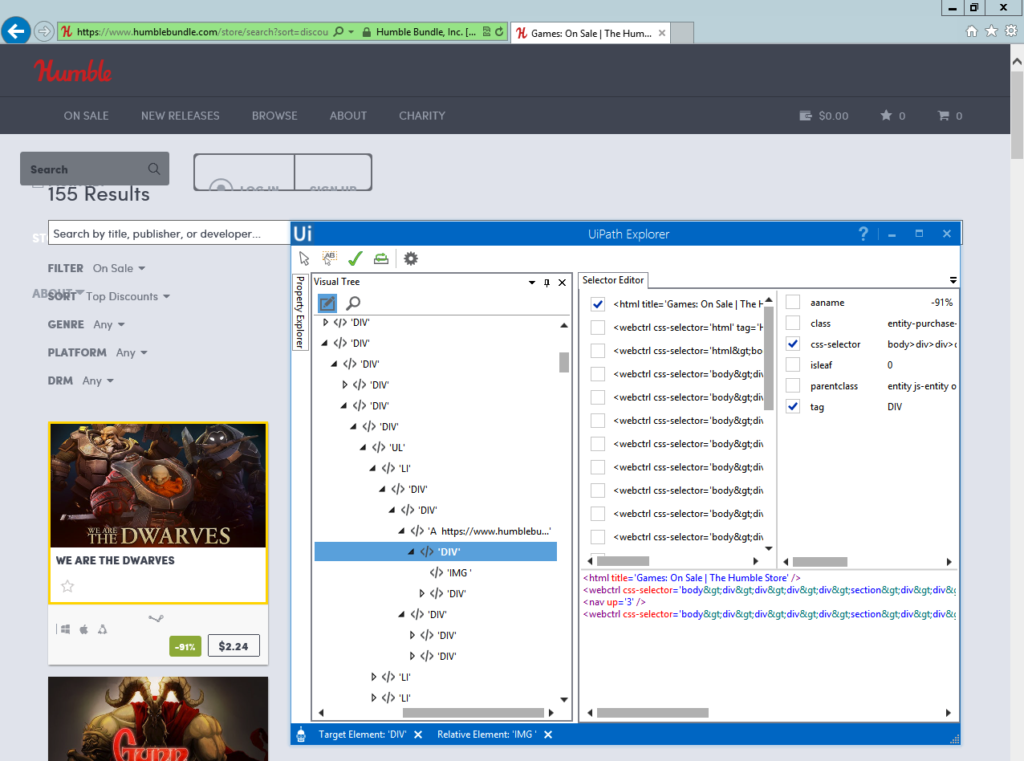
UiExplorer is similar to Kapow’s approach, yet it has to be opened separately (with a simple click from UiStudio). There’s highlighting, too, the DOM is being presented as a visual tree – so, not too many differences to be spotted here.
As mentioned last week, the built-in browser engine can help you building your robots quicker as Kapow knows and stores the state of wherever your currently are. Here’s an example with pagination: as we click forth and back through the different steps, the browser and DOM immediately get updated.
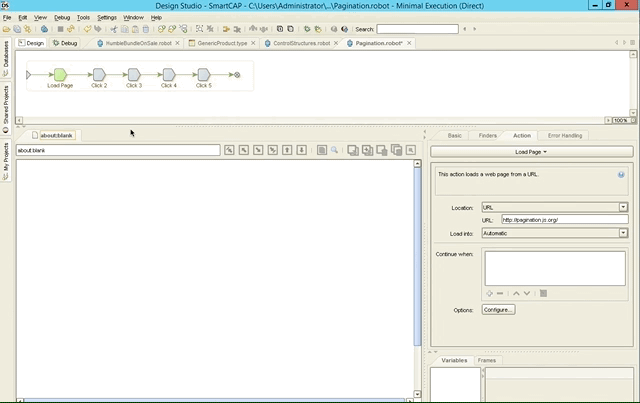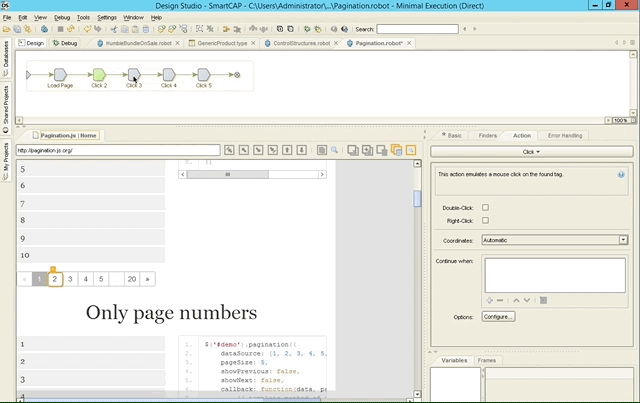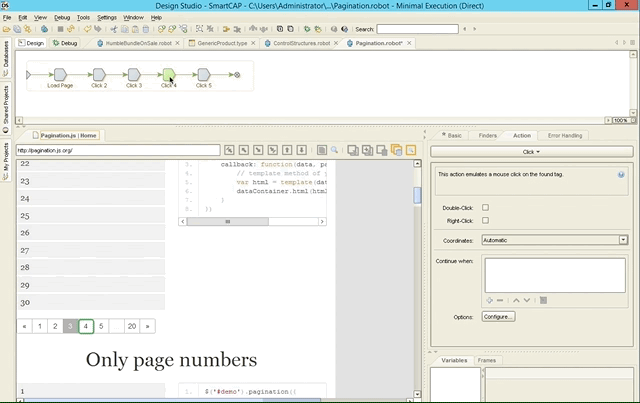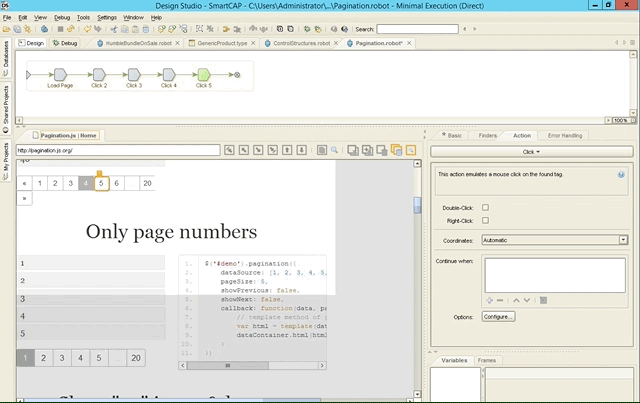
Conclusion & Verdict
While both Kapow and UiPath offer various methods of interacting with the DOM by simply pointing on certain elements, I like Kapow’s approach much better. You can clearly see that Kapow was built with Web Automation in mind – just take a look at the Design Studio alone – a big portion of it is used to display the web page along with the HTML. UiPath is different – Web Automation is done via an external application along with a plugin – so strictly speaking, it’s done via Desktop Automation.
Kapow saves you a lot of time again by immediately showing you the result, and allowing you to step back and forth at any time while updating or resetting the DOM to precisely where it was at that point. You can’t have that in UiPath – going back to an earlier step requires you to restart the robot and set a breakpoint, or work in a separate sequence.
As such, again – Kapow is the clear winner here.
Web Scraping
Scraping just one single line of text from a web page often isn’t enough. You may potentially want to extract dozens of items, spanning over multiple pages. Think of a web shop, for example: you want to extract every single item along with its title, price and discount. This is where looping comes into play.
Remember control structures, the for-each loop to be more precise? Instead of having a semi-automatic approach that tries finding similar elements as UiPath does, Kapow allows you to cycle through them in a loop that can often be created with a single click:
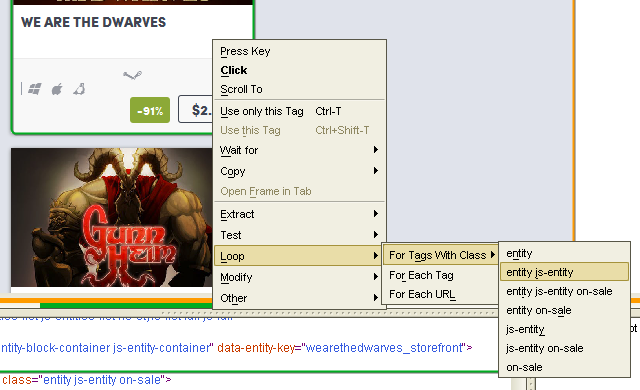
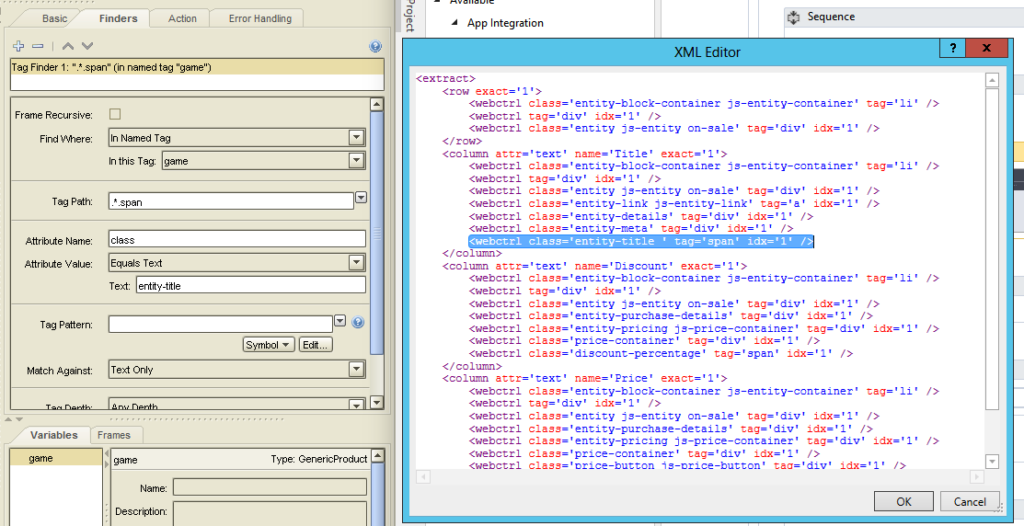
In the above sample only divs with the class entity js-entity will be considered, and it just took two clicks to build the entire loop along with the tag finder – a selector, i.e. something that ensures only the correct elements you’re looking for are considered. The same can be done in UiPath, too – but this time, the representation is much easier to understand in Kapow:
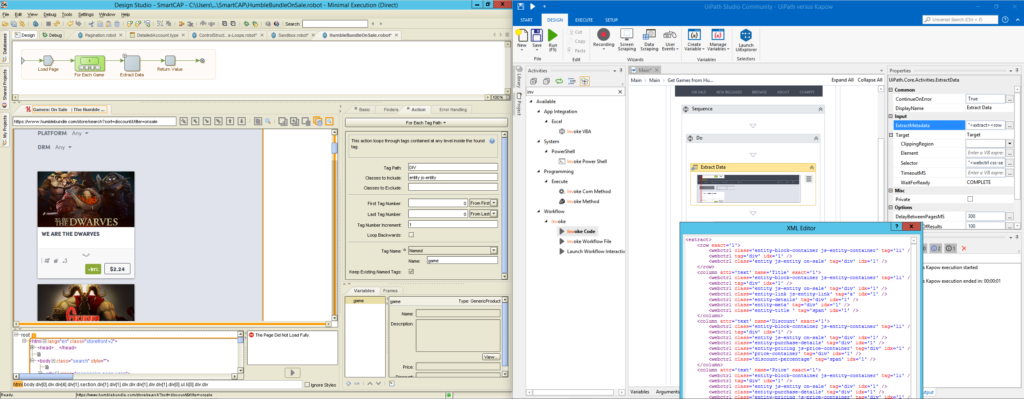
Kapow’s for-each loop clearly states that it will select divs with a class equal to entity js-entity, all of this can be seen in the properties window. A single item will be tagged as game and can from now on be referenced using this named tag. Thus, all future finders will be much easier to read, and should the structure of the page change, often just one change to the named tag is necessary as all future elements work with a relative tag pattern.
UiPath on the other hand shows the configuration in an XML file that has been automatically created by UiExplorer. Yet, editing it or parts of it requires more attention, and it’s not too obvious what is going on just be looking at the individual steps. The same is true for the three individual pieces of information we want to retrieve, namely the title of the game, the discount, and the price:
One useful feature of UiPath it how it deals with HTML tables – you can extract them with a few clicks, even with the table spanning over multiple pages.:
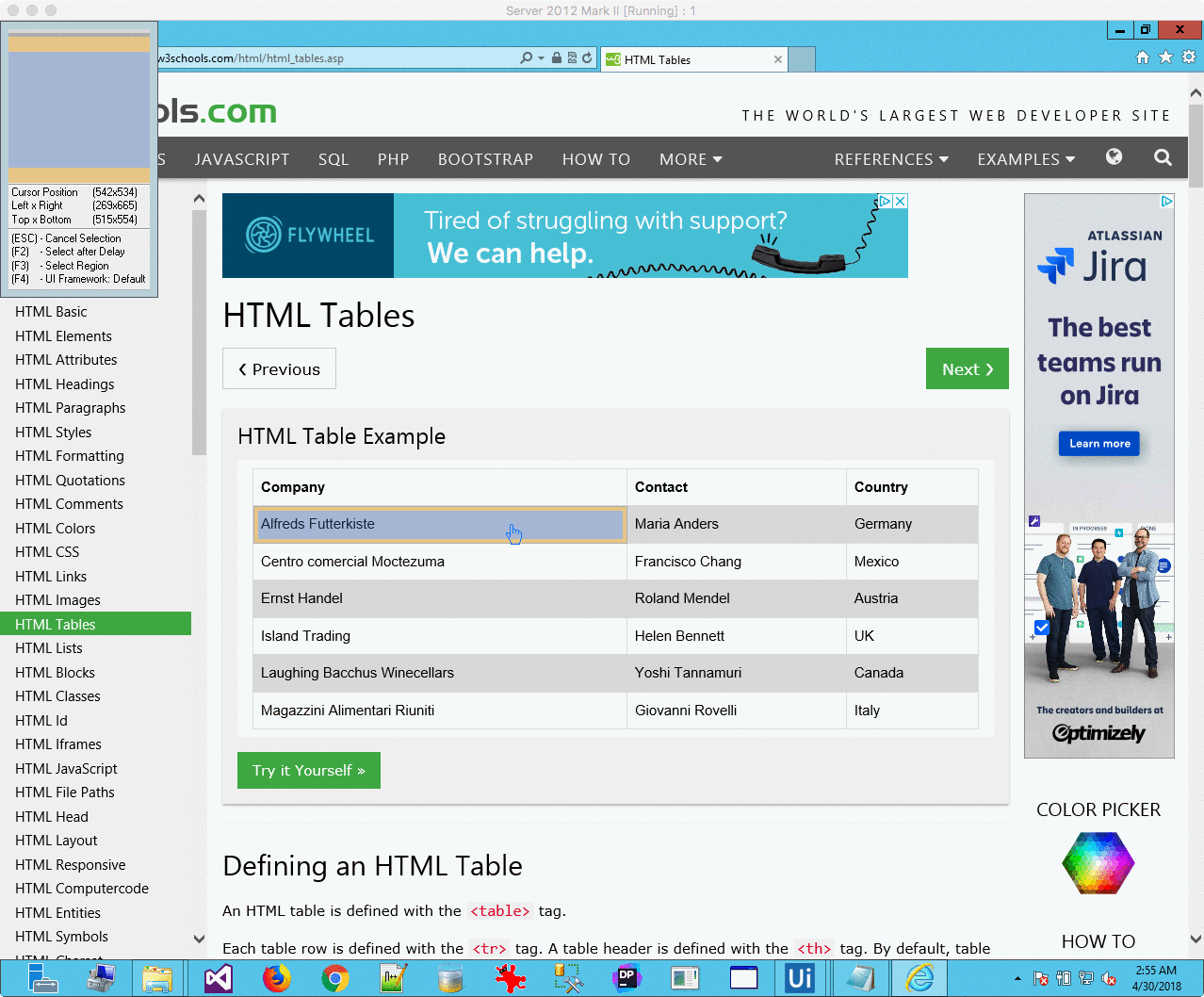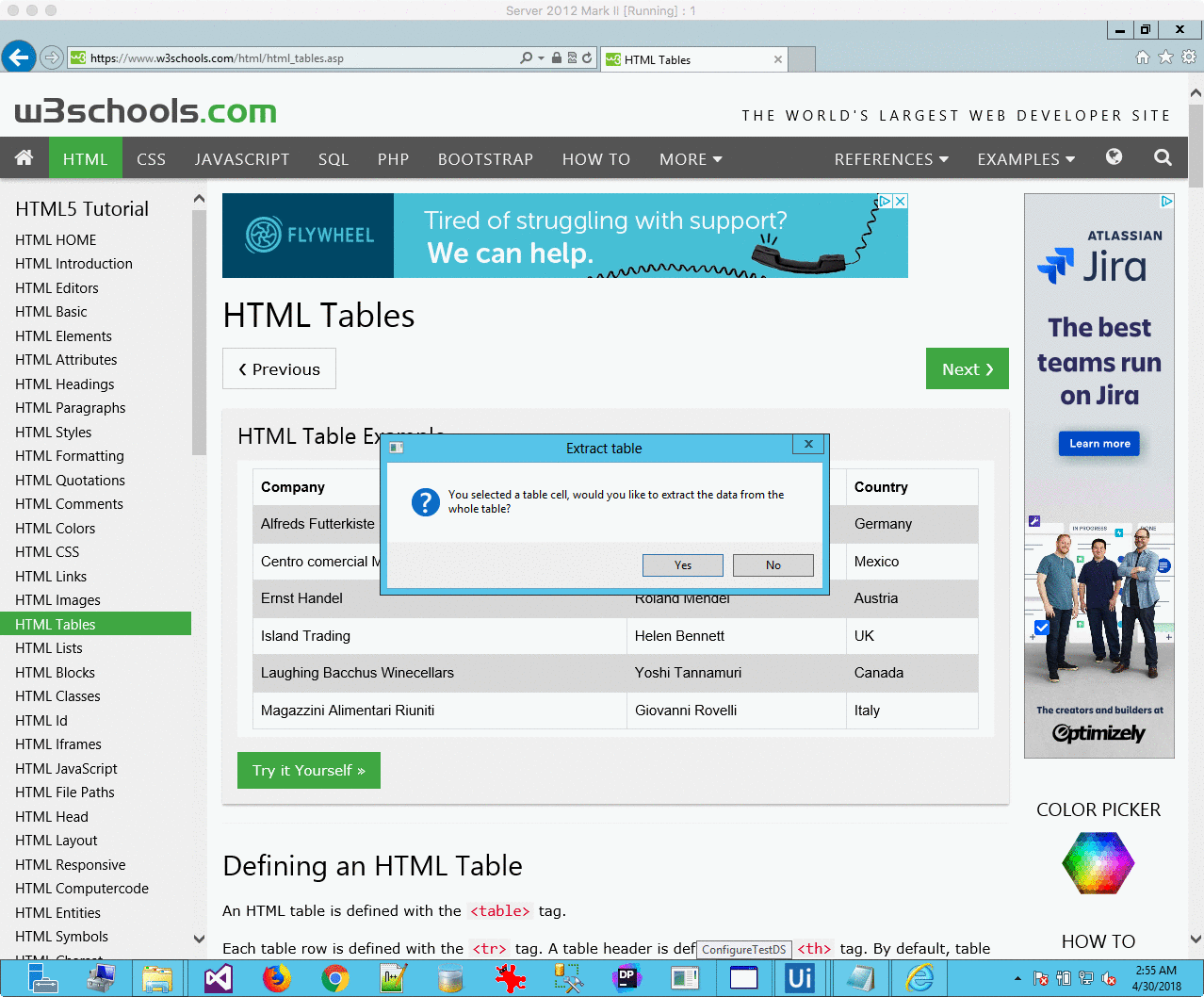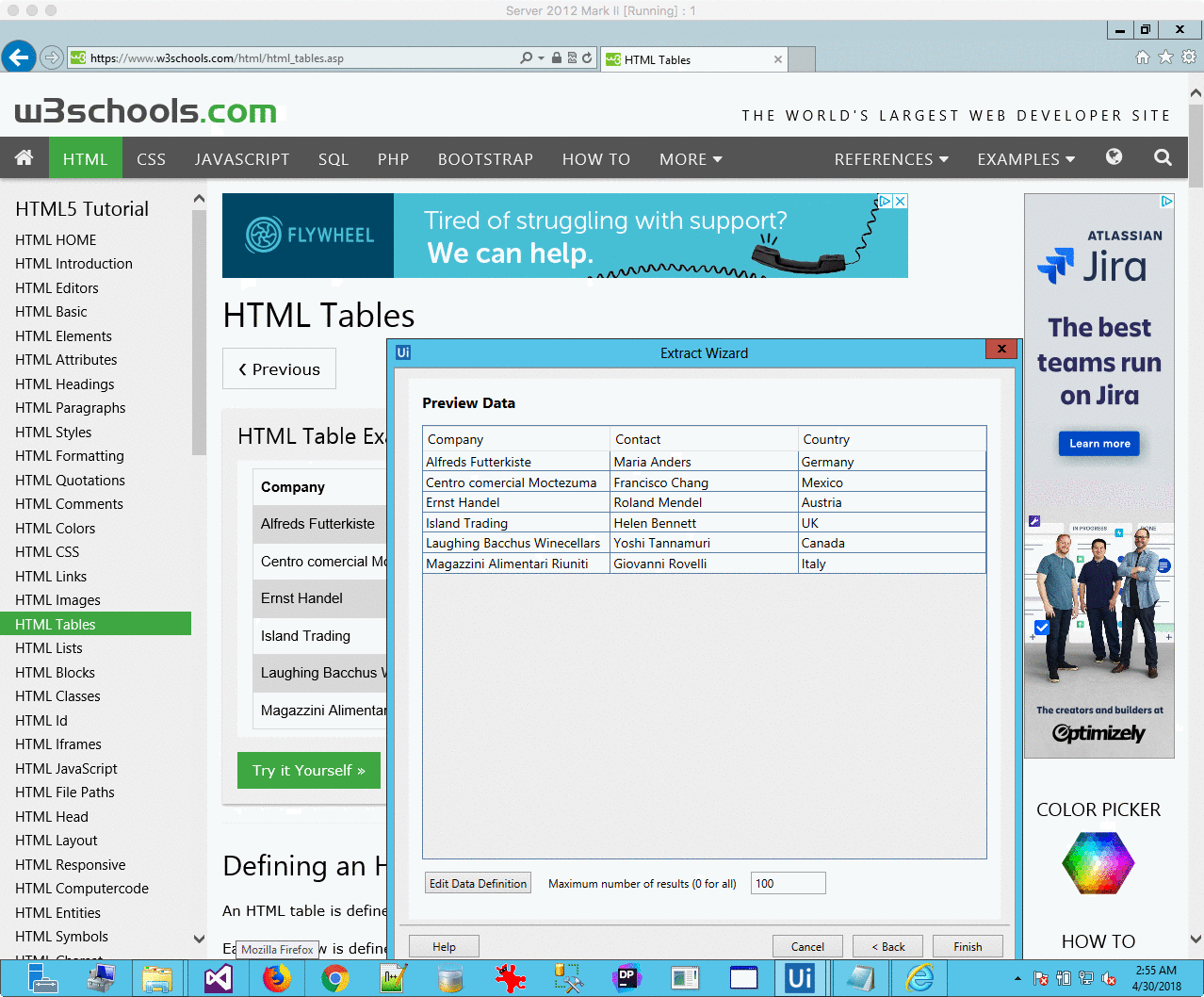
While Kapow can extract these tables as well, you will have to use the For Each action again, and then map each cell individually.
Another feature that Kapow offers is called tagging – you can tag just any element on a page and use it as a named tag. Look at the table above and imagine what would happen if the web developers at w3schools decide to move it to a different division of the page – this would break both robots in Kapow and UiPath. However, as with tagging the columns were relative to a table, just changing the named tag in Kapow is sufficient to get the robot working again. In UiPath (or without named tags in Kapow) you would either need to change many more paths, or use wildcards in paths, which both solutions allow.
Conclusion & Verdict
Both Kapow and UiPath are efficient scrapers, UiPath has some wizards that will make your job easier – for example, you can just click the first and last item in a list, and let UiPath work out the appropriate path for you. You can even do this a second time to have UiPath determine better path finders automatically, which of course doesn’t work all the time. If there is a significant difference that sets one product apart, it is not found in this section – I call it a draw between Kapow and UiPath.
Web Interaction
Apart from just scraping information from the web, Robots need to be able to interact with certain elements such as textboxes, radio buttons, checkboxes, and drop-downs. Both Kapow and UiPath easily help you to do so – you can click on any element, send text to textboxes, and can just select one many options in a drop-down. Imagine a robot that opens Amazon.com, searches for “Bestsellers”, checks “Get It by Tomorrow”, and finally sorts by customer reviews – here’s how the robots look in Kapow and UiPath, respectively:

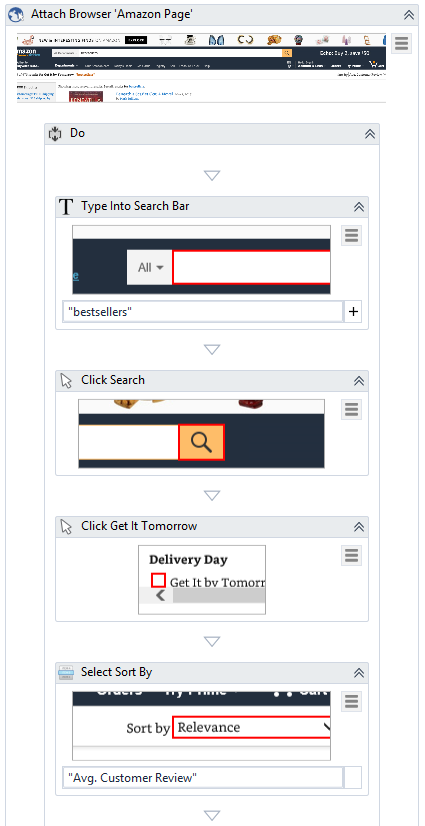
You’ll immediately see my favourite feature in UiPath: it automatically takes screenshots for each action, and in general – understanding the whole process is much easier. Just looking at the actions in the Kapow robot doesn’t tell you anything – in fact, you will have to rename many of them yourself to know what’s going on (to be fair, that’s what I keep doing in UiPath, too).
Conclusion & Verdict
Well, this isn’t a section about the best presentation but about interaction with web pages – and on that level, I cannot see a large difference that sets either solution apart. Both Kapow and UiPath can interact just nicely with web pages, and while Kapow has dedicated actions to scroll to a certain element to deal with endless scrolling pages (think of Twitter or Instagram), UiPath can just utilize the browser to scroll down indefinitely. Another draw!
Dealing with JavaScript
Let’s face it – the typeless monstrosity is everywhere. And while I maintain my love/hate-relationship with JavaScript, you’ll need your robots to be able to deal with it. The great news is: neither Kapow nor UiPath will have many issues with JavaScript. Kapow has an option to disable it either for the full robot or individual steps, which can result in much faster load times and a cleaner page layout, and for UiPath you could just disable it in the browser’s settings – yet good luck finding a page in 2018 that will yield many meaningful results with JavaScript being disabled.
In the years I’ve been working with Kapow I only had one issue with one particular page that used the React framework where Kapow would show an infinite throbber and just not the updated page. UiPath on the other hand utilizes the browser directly (or indirectly, via a plug-in). So, if your browser can display it, UiPath can work with it.
Conclusion & Verdict
Not much to add here – as both solutions support JavaScript, there is no winner or loser here.
Conquering the Web
Web Automation is somewhat a home game for Kapow, this is what they’ve been doing for many years – naturally, there are many features present that offer much more than just simple scraping or interacting with pages.
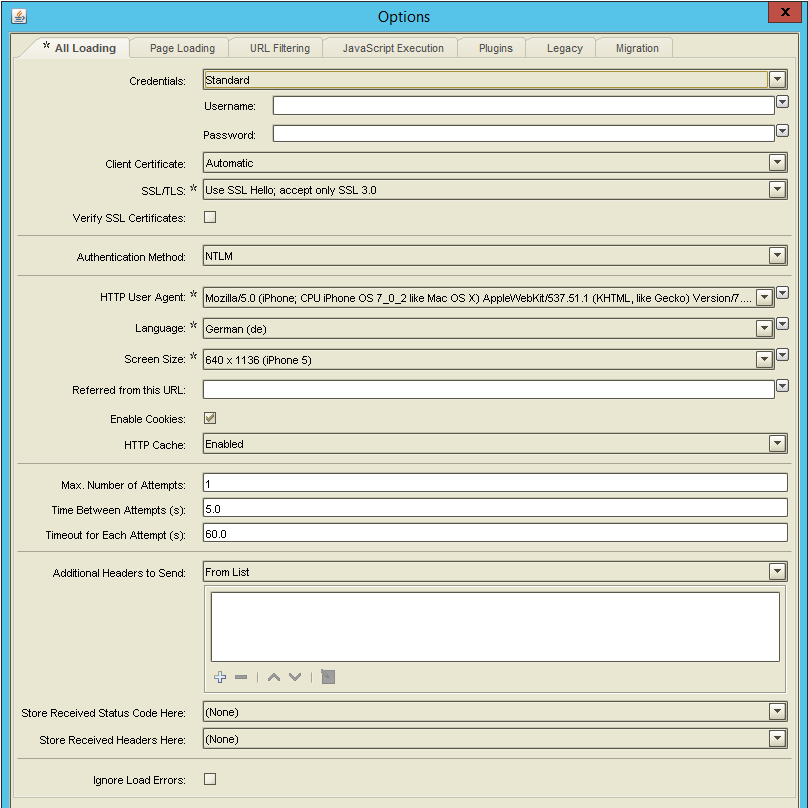
If you want, you can setup Kapow to hit a web page with a different client and language every time. For example, the first request is sent from an iPhone, the next one mimicking Internet Explorer on an English operating system, with a different resolution this time. Then, you might want to change your IP address and hit the page again. Heck, you can even emulate random mouse movements, wait for elements to (re-)appear, wait for fixed periods of time, deal with infinite scrolling, and much more.
Conclusion & Verdict
There is little that can stop you with Kapow – a page blocking your IP after exceeding a certain amount of requests per hour? Just hit them with different clients and route all traffic over Tor. Filter certain URLs, execute custom JavaScript, change HTTP headers – you name it. Besides from routing traffic over a VPN network, everything is already built into Kapow and ready to use. This is a major victory for Kapow.
Conclusion and Outlook
This covers the second part of the Kapow vs. UiPath series. Web Automation was a home play for Kapow, yet things may look quite different next week. Here’s the summary:
- General Approach: Kapow++
- Interacting with the DOM: Kapow++
- Web Scraping: Neutral
- Web Interaction: Neutral
- Dealing with JavaScript: Neutral
- Conquering the Web: Kapow++
Next week I plan on covering Desktop and Citrix Automation – stay tuned.