Collections are a great thing. They allow you to organize your objects in a quick and easy way, adding and deleting as you please. The only shame is: WinWrap Basic does not add any support for collections out of the box. However, there is a simple way: KTM includes contains the CscCollection class that you can and should use to organize your objects. CscCollections are organized just like a dictionary: there is a unique id, i.e. the key, and the name, i.e. the value.
Here’s a simple example: our dictionary will hold fields, locators and all words of the xDoc. Then, we’ll access the fields by the key and store them into a fresh field object:
Dim c As New CscCollection
c.Add(pXDoc.Fields, "fields")
c.Add(pXDoc.Locators, "locs")
c.Add(pXDoc.Words, "words")
Dim f As CscXDocFields
Set f = c.ItemByName("fields")
A more complex example: let’s assume the following use case – you want to create a histogram for the words present on your document.
Conventional approaches may not include arrays that you’d constantly redim. With collections, your task is way easier. Note that we’re going to use multiple dictionaries however. One will contain all unique words (the words text as key, to be precise), and for the value, we’ll have a new collection containing all word themselves as objects.
Here’s the pseudo code:
- For each word, check if the collection already holds its text (i.e. the key).
- If the key was found, add the word to the value.
- If the key was not found, create a new key and a new collection as value. Then, add the word to that new collection.
Sounds confusing? This graphic explains it:
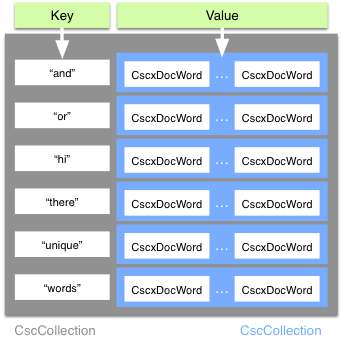
The gray are represents a collection of unique words. The key is the text of that word, for example “and”, “or”, “there”. For the values, there are n additional collections, each holding as many instances of the respective word found. For example, if the document would contain seven “ands”, there would be seven words inside the first blue collection.
Here’s the code (I use a script locator here):
Private Sub SL_Histogram_LocateAlternatives(ByVal pXDoc As CASCADELib.CscXDocument, ByVal pLocator As CASCADELib.CscXDocField)
Dim histogram As New CscCollection
Dim wordCount As Long, histogramCount As Long
For wordCount = 0 To pXDoc.Words.Count - 1
'For Each word, check If the collection already holds its Text (i.e. the key).
If histogram.ItemNameExists(pXDoc.Words(wordCount).Text) Then
'If the key was found, add the word To the value.
histogram.ItemByName(pXDoc.Words(wordCount).Text).Add(pXDoc.Words(wordCount), CStr(wordCount))
Else
'If the key was Not found, create a new key And a new collection As value. Then, add the word To that new collection.
Dim c As CscCollection
Set c = New CscCollection
c.Add(pXDoc.Words(wordCount), CStr(wordCount))
histogram.Add(c, pXDoc.Words(wordCount).Text)
End If
Next
OutputHistogram(histogram)
End Sub
Here’s the helper sub that outputs the histogram to the debug view:
Private Sub OutputHistogram(c As CscCollection)
Debug.Clear
Dim i As Long
For i = 1 To c.Count
Debug.Print c.ItemName(i) + ";" + c(i).Count
Next
End Sub
Now, we can tell the following:
How many unique words are present on the document? A simple count provides us with that information.
Furthermore, by counting each word’s words (Inception, anyone?), we’ll finally have our histogram!
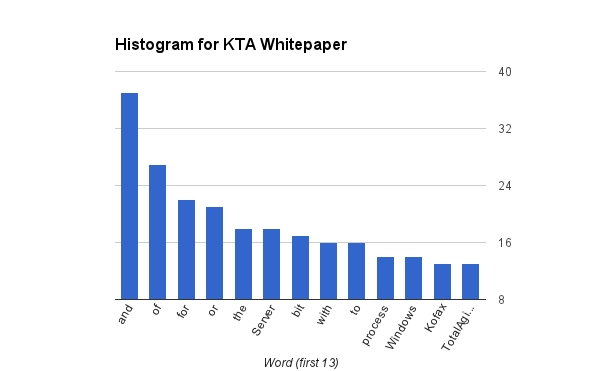
The above image shows the top 13 words by count of the KTA Whitepaper. By the way:
Kudos to David Wright for lending me his brain when writing this algorithm 😉