Quite often, I find both partners and customers overwhelmed with the task of document classification in KTM. And surprisingly often the classification challenge is not a technical or mathematical, but a conceptual one. In this post I will present a list of five different, yet interdependent issues. The list is not exhaustive, and I’d really like to hear about your thoughts and problems encountered.
Usually, that’s what you hear from a customer looking for your help:
Classifying all our mail is killing us. We need a tool that helps us to deal with this time-consuming task.
One of your next questions usually is: “How many document classes are we talking about,” and their answer usually is, “oh, a few hundred”.
1. Too many classes!
Here we have identified our first problem: too many classes. Kofax uses state of the art technology to identify the most likely class a document belongs to, quite similar to how spam detection works. There is a set of certain features shared by all documents of a single class. Think of it in an abstract way: you want to classify animals. There are distinct features shared by certain classes of animals: having fur and four legs, we may assume a mammal. When it has feathers and a beak, it’s most likely a bird. With some exceptions, of course: the Weka bird can not fly, yet is a bird. Naturally, the more classes there are, the more difficult it will become to differentiate between distinct elements.
So, if your customer’s statement was, “we have a few hundred classes”, your next question should be, ” how many of those account for the majority of your mails?”. The Pareto principle serves us quite well here: in most cases, 80% of the total volume processed is already covered by 20% of all classes. So, if your customer said that they had 100, then 20 classes will cover 80 out of 100 e-mails. Here’s the deal: you should entirely focus on those 20 classes. Why? Well, Pareto applies well again when it comes to giving the customer an offer. 20 classes can be set up with 20% of all the (theoretical) effort required to get the system working. Remember, those 20 classes account for 80% of the volume. In order to “get the rest done”, 80% of all the effort is to be invested. Usually that’s a bad idea, and that’s why you want to keep the amount of total classes low.
Take a look at the following table – this represents a real-life example of a customer. The class names were removed, but the volume is the interesting part here: initially, they told us they had 90 classes. As you can see, 6 classes make up for 80% of the annual volume – and 10 classes account for more than 90%. You should not waste your time (and their money) on the remaining ones.

2. Small sample size
The good news is: you don’t have to worry about finding said features, Kofax offers classifiers that can derive features themselves from samples provided. This leads us to the second problem, too small sample sizes. Quite often, customers expect us to classify large amounts of documents per day, several hundreds, sometimes even thousands. Surprisingly, the same customers seem to be unwilling or unable to provide you with a representative set of sample data: “here are twenty samples for customer complaints, now go and build your model” is what I often hear. No, I’m not joking. That can’t work, and here’s a simple example why. Imagine there are presidential elections taking place in your country: would you ask five random individual on the street whom they’d vote for and expect a realistic representation of the results? Well maybe, of you’re lucky. What’s more likely is that your sample size is way too small to represent the total population (no statistical pun intended). There are some great forecasts, but check how larger their sample size usually is: sometimes a few thousand individuals were asked. Bad sampling can lead to many errors as your model may have to little information available to generate distinct features from, and a small test set can additionally lead to a false sense of accuracy: it seems to work fine for your 50 examples. In a nutshell, the issue is perfectly describes in a quote from David Wright:
A customer who says that they cannot provide you with 1000 examples, but expects your solution to produce 1000 per day, is being neither realistic nor cooperative.
3. How good is your model?
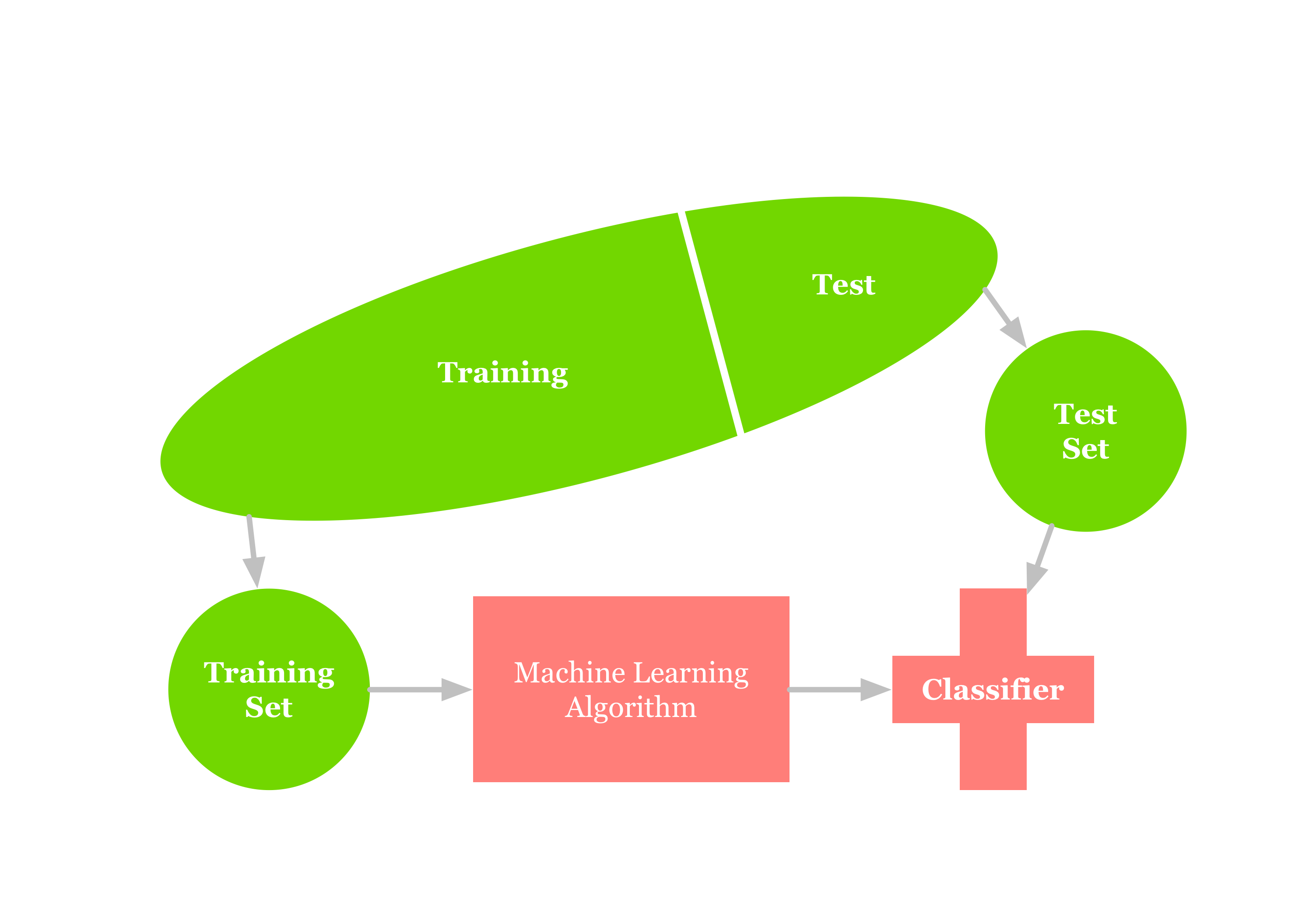
Now, equipped with a representative set of documents, we can focus on the third problem: how good is your model? “Without data you’re just another person with an opinion”, to quote Deming another time. Good news, again: Transformations offers the right tool for this job: Classification Benchmarking. And as you already solved problem number two, you already have plenty of samples! The next steep is to separate them into two sets: a training set and a test set. I won’t dive into the details here, usually you want to have more training data so that enough samples are available for your model to contain all relevant features. At the very same time you want a test set that still is representative for the documents to be processed. As said, this topic alone is so complex that it’d justify its own article, so here’s one word of advice: NEVER mix training and test documents. Doing so can be considered cheating yourself.
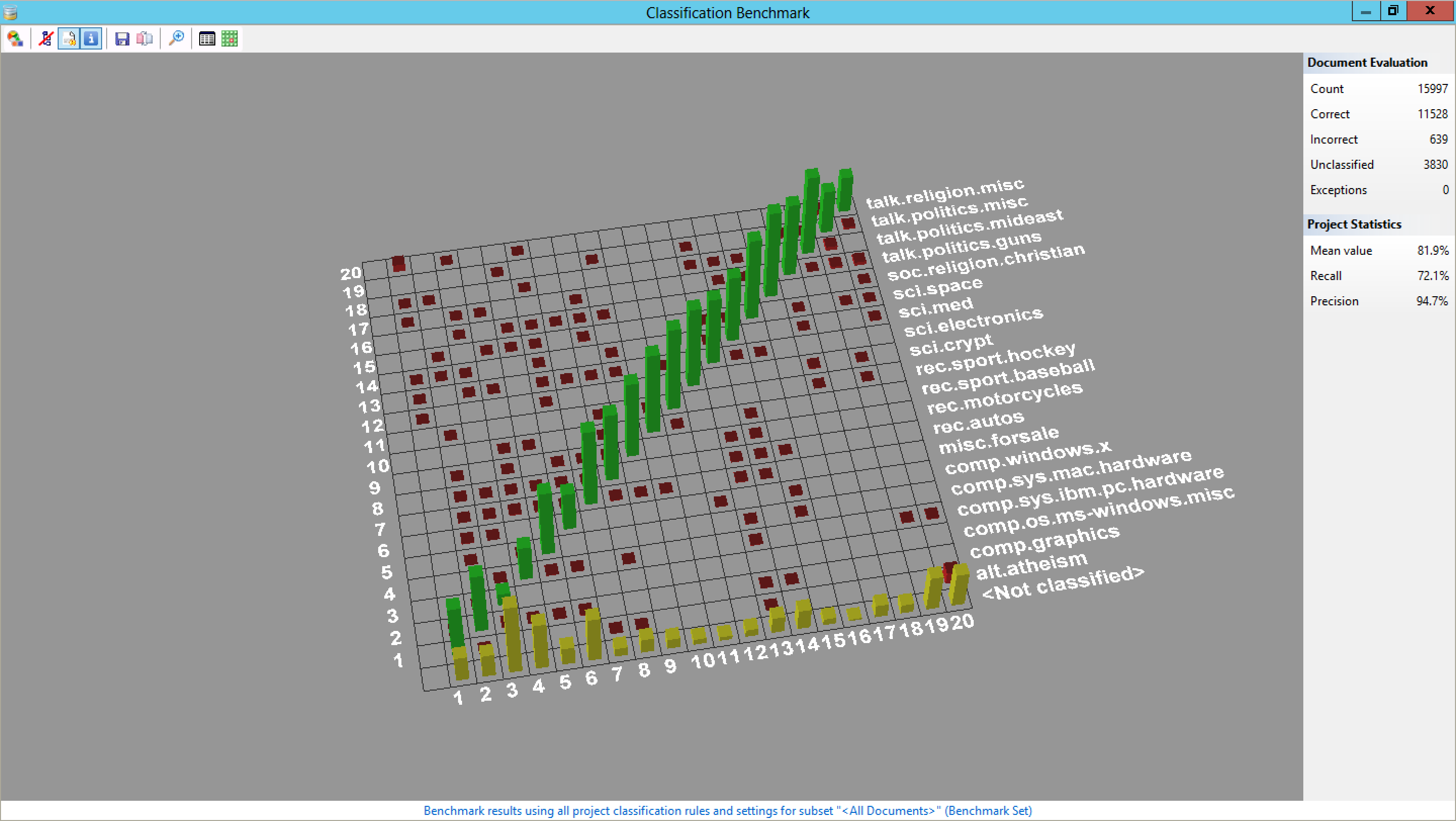
Here’s a screenshot of Classification Benchmarking in action. Not only does it tell you the quality of your model, expressed by precision and recall, it also shows you where problems can be expected. In the below example, the precision is quite high. That’s good as it means Kofax determines the correct class for the majority of your samples. Recall is high as well, and that’s also good: that indicates that most relevant documents are identified after all. In addition, we see that there are some issues to be expected with the classes about religion and atheism. That’s only natural, as documents from both classes share a very similar vocabulary (apparently atheists talk about God, too) – that brings us to the next problem.
4. The world isn’t just black and white.
That’s true for your classification task, as well: everything is fuzzy when it comes to classifying a single document, and that’s why Kofax determines a likelihood for each class. A document can be a complaint and an information request at the same time. In addition, the more classes you have, the more likely it will become that one document belongs to either class. The above example about religion and atheism showed us that – when classes share a common vocabulary, a distinct result hardly can be expected. It is vital to make your customers aware of that fact, and maybe even offer them a solution that allows for documents being tagged as multiple classes.
The above example leads to another problem: sometimes all the customer wants to know is a tag that represents the class(es) of an individual document. Sometimes no further specialized locators are needed: imagine that all you want to do besides tagging is deriving the issuer of an email, for example with a database locator. This is basically nothing more than using classification as a label: the final class(es) can be considered as metadata, stored in a (table) field.

5. Departments aren’t good labels
Finally, there is another problem: departments are bad labels for classes. That’s what I see quite often, in fact: instead of providing us with classes that represent the very essence of a document, customers give us the names of the departments dedicated to receiving said documents. I’m not saying that this never works, but usually it’s a bad idea. Imagine the accounting department: they do receive invoices and sometimes delivery notes, but generic correspondence as well. If you had that department as your label, it would contain documents shared by many others as well: generic correspondence.
Focus on the essence of the document first: in above case, we’d have invoices, delivery notes and correspondence. Routing them to the right class is easy for the first two classes; for the correspondence class, you’d need additional mechanics in order to address the correct department: for example, you could make use of a database locator detecting the right employee – in most cases, either their email address will be present, or you will find their last and first names on the document. However, the document itself is generic correspondence, no matter which department is the final destination. If you had multiple correspondence classes, the classifier may have a hard time deriving unique features for each class, resulting in a lot of uncertainly.
So, that covers up my top fives. What are your experiences with classification projects? Can you think of other issues, do you have a story to tell? Feel free to contact me any time.