When it comes to representation learning, you usually need to create two distinct document sets: one for training your classifier, and one for testing your model. It’s essential not to mix documents, i.e. the test set must not contain data from the training set, and vice versa. This task sometimes can become quite time-consuming and annoying, especially if you consider cross validation when you need to create for example 10 different sets.
Since version 6.0, KTM supports splitting a document set, but that feature is far from perfect: you can only split one subset at a time, so if you have a lot of subsets, this task is quite time-consuming.
Finally, I decided to write a small helper utility to save me some time. Here’s what it can do:
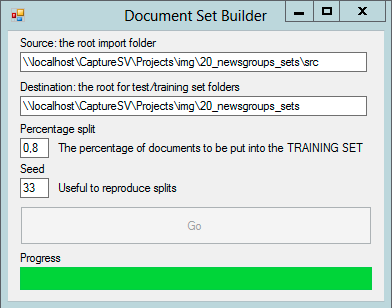
- The root folder contains subfolders with the documents you want to split. Note that additional subfolders are supported as well, this tool works recursive;
- The destination will later on contain two directories: one for test, one for training documents;
- The percentage split allows you to set a value from 0 to 1 – for example 0,8 will put 80% of the documents to the training folder;
- The seed allows you to control the randomized split, and helps you to reproduce the same split later again.
This is what you get:
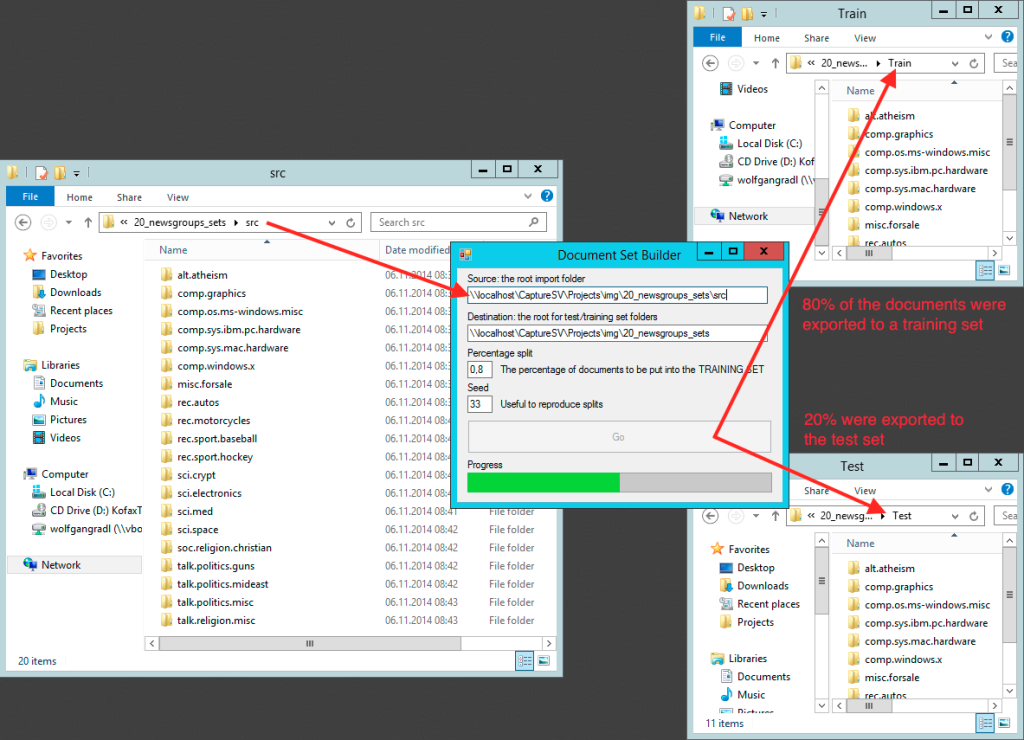
As you can see, the tool allows to quickly generate test and training sets. So, if you want to perform cross-validation on your own, just start it up 10 times, put in different seeds and don’t forget to move the test and training folder to a dedicated directory. You can download the tool here: DocumentSetBuilder.
Feel free to share your thoughts, report any issues encountered or feature requests.